Method
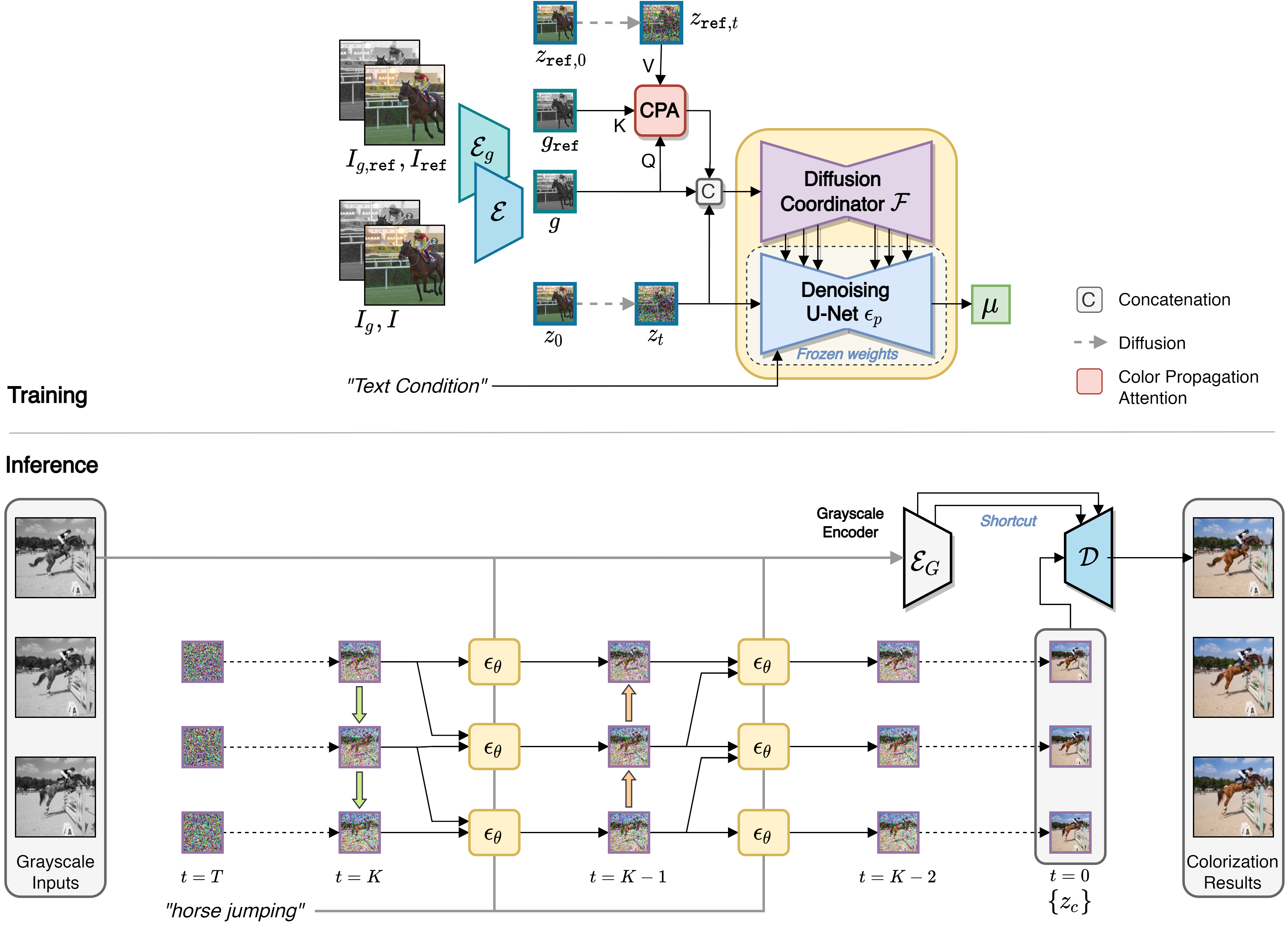
- We extend the pre-trained Stable Diffusion model to a reference-based frame colorization model. With the adapter-based mechanism, we obtain a conditional text-to-image latent diffusion model that leverages the power of the pre-trained Stable Diffusion model to render colors in the latent space \(z_c\), according to the visual semantics of the grayscale input \(g=\mathcal{E_g}(I_g)\), the text input, and the reference color latent \(z_{\texttt{ref},t}\).
- During the inference, for each frame in the input grayscale video, we perform a parallel sampling process. Each sampling step for a particular frame is conditioned on the latent information from the previous sampling step of an adjacent frame. Essentially, the Color Propagation Attention and the Alternated Sampling Strategy coordinate the reverse diffusion process and enable bidirectional propagation of color information between adjacent frames to ensure consistency in colorization over time.